Unity 基础 AI 开发
Intro
人工智能(Artificial Intelligence,简称AI),是指由人工制造出来的系统所表现出来的模拟人类的智能活动,通常也指通过计算机实现的这类智能。在游戏中,对于AI,应该关注的问题是如何让游戏角色能像人或动物那样“感知”、“思考”和”行动”,让游戏中的角色看上去像具有真实的人或动物的反应。
事实上,对于游戏中的AI角色,可以认为它们一直处于感知(Sense)→思考(Think)→行动(Act)的循环中。
- 感知:是AI角色与游戏世界的接口,负责在游戏运行过程中不断感知周围环境,读取游戏状态和数据,为思考和决策收集信息。例如,是否有敌人接近等。
- 思考:利用感知的结果选择行为,在多种可能性之间切换。例如,战斗还是逃跑?躲到哪里?一般说来,这是决策系统的任务,有时也可能简单地与感知合二为一。
- 行动:发出命令、更新状态、寻路、播放声音动画,也包括生命值减少等。这是运动系统、动画系统和物理系统的任务,而动画和物理系统由游戏引擎提供支持。
游戏AI的架构模型
尽管每种游戏需要的AI技术都有所不同,但绝大多数现代游戏中对AI的需求都可以用三种基本能力来
概括。
运动:移动角色的能力;
决策:做出决策的能力;
战略:战略战术思考的能力。
block-beta
columns 3
小队AI:1
block:team:2
columns 1
战略层:1
end
角色AI:1
block:character:2
columns 1
决策层:1
运动层:1
end
引擎底层:1
block:engine:2
columns 2
动画系统
物理仿真系统
end
运动层
导航和寻路是AI运动层的主要任务,它决定了角色的移动路径。当然,更细致的表现需要动画层的配合。
运动层包含的算法能够把上层做出的角色转化为运动。
举例来说,当一个 AI 角色做出攻击玩家的决策时,运动层会利用与移动相关的算法使玩家接近角色的位置来执行这个决策,然后才会播放攻击动画,以及处理角色或玩家的生命值等。
决策层
决策层的任务是决定玩家在下一时间该做什么。
一般情况下,每个角色都有许多不同的行为可以选择,每个时间区间里,决策系统都需要判断哪些行为是最合适的。当决策系统做出决策后,需要依赖运动层和动画系统来执行决策。
一些决策可能需要运动层来执行。例如近身攻击需要首先靠近攻击目标。也有一些决策不需要运动层支持,只需要播放动画,或者是更新游戏状态即可。
决策层的功能可以利用有限状态机或行为树技术实现,也可以采用更复杂的 AI 技术,比如模糊状态机、神经网络等。
战略层
大多数游戏只需要使用运动层和战略层就足以实现很复杂的功能(事实上大部分游戏也只用到了这两个层次),但是如果需要团队协作,则还需要某些战略 AI 。
战略指的是一组角色的总体行为,这时 AI 算法并不只控制单个角色,而是会影响到多个角色的行为。
小组中每个角色可以有它们自己的决策层和运动算法,但总体上,他们的决策层会受到团队战略的影响。
实现 AI 角色的自主移动——操纵行为
1986年,Craig Reynolds提出了“集群”和“操控行为”的概念,用来仿真鸟的行为。他的论文发表在1987年的SIGGRAPH会议上,他还利用这种方法做了一个动画短片 Stanley & Stella in Breaking the Ice,鸟群显示出某种一致性、聚合性,但又并不是完全整齐排列地向一个方向飞翔或游动,而是呈现一定的随机性。鸟群的行为看上去很自然、逼真,因此产生了深远的影响。
“操控行为”是指操作控制角色,让它们能以模拟真实的方式在游戏世界中移动。它的工作方式是通过产生一定大小和方向的操控力,使角色以某种方式运动。
操控行为包括一组基本“行为”。对于单独的AI角色,基本操控行为包括:
使角色靠近或离开目标的“Seek ”、“Flee”行为;
当角色接近目标时使它减速的“Arrival”行为;
使捕猎者追逐猎物的“Pursuit”行为;
使猎物逃离捕猎者的“Evade”行为;
使角色在游戏世界中随机徘徊的“Wander”行为;
使角色沿着某条预定路径移动的“Path Following”行为;
使角色避开障碍物的“Obstacle Avoidance”行为等。
基本行为中的每一个行为,都产生相应的操控力,将这些操控力以一定的方式组合起来(实际上就相当于将这些基本“行为”进行了不同的组合),就能够得到更复杂的“行为”,从而实现更为高级的目标。
对于组成小队或群体的多个AI角色,包括基本的组行为如下。
与其他相邻角色保持一定距离的“Separation”行为;
与其他相邻角色保持一致朝向的“Alignment”行为;
靠近其他相邻角色的“Cohesion”行为。
无论整个群体中有多少个个体,对于每个个体,计算的复杂性都是有限的,通过这种简单的计算,就可以产生逼真的效果。采用这项技术,两个相似的鸟群,即使是飞过相同的路线,它们的行为也是不同的。如果将这种真实性与其他采用中心控制机制的AI方法相比,就更容易看到它的特别之处。
这种方法的缺点在于,由于它无法预测,可能会出现无法预料的行为,也因此效果更真实、自然。为了得到更可靠的结果,在使用时许多参数需要通过实验调整。
个体 AI 角色的操控行为
靠近
操控行为中的靠近是指,指定一个目标位置,根据当前的运动速度向量,返回一个操控AI角色到达该目标位置的“操控力”,使AI角色自动向该位置移动。
要想让AI角色靠近目标,首先需要计算出AI角色在理想情况下到达目标的预期速度。该速度可以看作是从AI角色的当前位置到目标位置的向量。操控向量是预期速度与AI角色当前速度的差,该向量大小随着当前位置变化而变化。
离开
离开和靠近行为正好相反,它产生一个操控AI角色离开目标的力,而不是靠近目标的力。它们之间唯一的区别是DesiredVelocity具有相反的方向。
抵达
有时我们希望AI角色能够减速并停到目标位置,避免冲过目标,例如,车辆在接近十字路口时逐渐减速,然后停在路口处,这时就需要用到抵达行为。
在角色距离目标较远时,抵达与靠近行为的状态是一样的,但是接近目标时不再是全速向目标移动,而代之以使AI角色减速,直到最终恰好停在目标位置。何时开始减速是通过参数进行设置的,这个参数可以看成是停止半径。当角色在停止半径之外时,以最大速度移动;当角色进入停止半径之内时,逐渐减小预期速度,直到减小为0。这个参数的设置很关键,它决定了抵达行为的最终效果。
追逐
追逐行为与靠近行为很相似,只不过目标不再是静止不动,而是另一个可移动的角色。最简单的追逃方式是直接向目标的当前位置靠近,不过这样看上去很不真实。
当动物追逐猎物的时候,绝不是直接向猎物的当前位置奔跑,而是预测猎物的未来位置,然后向着未来位置的方向追去,这样才能在最短时间内追上猎物。在AI中,把这种操控行为称为“追逐”。
我们可以使用一个简单的预测器,在每一帧重新计算它的值。假设采用一个线性预测器,又假设在预测间隔T时间内角色不会转向,角色经过时间T之后的未来位置可以用当前速度乘以T来确定,然后把得到的值加到角色的当前位置上,就可以得到预测位置了。最后,再以预测位置作为目标,应用靠近行为就可以了。
实现追逐行为的一个关键是如何确定预测间隔T。可以把它设为一个常数,也可以当追逐者距离目标较远时设为较大的值,而接近目标时设为较小的值。
这里,设定预测时间和追逐者与逃避者之间的距离成正比,与二者的速度成反比。
一些情况下,追逐可能会提前结束。例如,如果逃避者在前面,几乎面对追逐者,那么追逐者应该直接向逃避者的当前位置移动。二者之间的关系可以通过计算逃避者朝向向量与AI角色朝向向量的点积得到,在下面代码中,逃避者朝向的反向和AI角色的朝向必须大约在20度范围之内,才可以被认为是面对着的。
逃避
逃避行为是指使猎物躲避捕猎者。举例来说,鹿被狼追逐,鹿要不断变换逃跑方向,试图逃离狼预测的追逐方向。
逃避行为与追逐行为的不同是它试图使AI角色逃离预测位置。实现追逐行为的一个关键是如何确定预测间隔T,可以把它设为一个常数,也可以当AI角色距离目标较远时,设为较大的值,而接近目标时,设为较小的值。
随机徘徊
随机徘徊操控行为就是让角色产生有真实感的随机移动。这会让玩家感觉到角色是有生命的,而且正在到处移动。
利用操控行为来实现随机徘徊有多种不同的方法,最简单的方式是利用前面所提到的靠近(Seek)行为。在游戏场景中随机地放置目标,让角色靠近目标,这样AI角色就会向目标移动,如果每隔一定时间(如几秒)就改变目标的位置,这样角色就永远靠近目标而又不能到达目标(即使到达,目标也会再次移动)。
这个方法很简单,粗略地看上去也很不错,但是最终结果可能不尽如意。角色有时会突然掉头,因为目标移动到了它的后面。Craig Reynolds提出的随机徘徊操控行为解决了这个问题。
解决问题的工作原理同内燃机的气缸曲轴传动相似,。在角色(气缸)通过连杆联结到曲轴上,目标被限定曲轴圆周上,移向目标(利用靠近行为)。为了看得更似随机徘徊,每帧给目标附加一个随机的位移,这样,目标便会沿着圆周不停地移动。将目标限制在这个圆周上,是为了对角色进行限制,使之不至于突然改变路线。这样,如果角色现在是在向右移动,下一时刻它仍然是在向右移动,只不过与上一时刻相比,有了一个小的角度差。利用不同的连杆长度(Wander距离)、角色到圆心的距离(Wander半径)、每帧随机偏移的大小,就可以产生各种不同的随机运动,像巡逻的士兵、惬意吃草的牛羊等。
路径跟随
就像赛车在赛道上需要导航一样,路径跟随会产生一个操控力,使AI角色沿着预先设置的轨迹,构成路径的一系列路点移动。
最简单的跟随路径方式是将当前路点设置为路点列表中的第1个路点,用靠近行为产生操控力来靠
近这个路点,直到非常接近这个点;然后寻找下一个路点,设置为当前路点,再次接近它。重复这样的过程直到到达路点列表中的最后一个路点,再根据需要决定是回到第1个路点,还是停止到这最后一个路点上。
在实现路径跟随行为时,需要设置一个“路点半径(radius)”参数,即当AI角色距离当前路点多远时,可以认为它已经到达当前路点,从而继续向下一个路点前进。
避开障碍
避开障碍行为是指操控AI角色避开路上的障碍物,例如在动物奔跑时避免与树、墙碰撞。当AI角色的行进路线上发现比较近的障碍时,产生一个“排斥力”,使AI角色远离这个障碍物;当前方发现多个障碍物时,只产生躲避最近的障碍物的操控力。这样,AI角色就会一个接一个地躲避这些障碍物。
在这个算法中,首先需要发现障碍物。每个AI角色唯一需要担心的障碍物就是挡在它行进路线前方的那些物体,其他远离的障碍物可以不必考虑。该算法的分析步骤如下。
(1):速度向量代表了AI角色的行进方向,可以利用这个速度向量生成一个新的向量ahead,它的方向与速度向量一致,但长度有所不同。这个ahead向量代表了AI角色的视线范围,其计算方法为:
1ahead = position + normalize(velocity) × MAX_SEE_AHEAD
ahead向量的长度(MAX_SEE_AHEAD )定义了AI角色能看到的距离。MAX_SEE_AHEAD 的值越大,AI角色看到障碍的时间就越早,因此,它开始躲避障碍的时间也越早。
(2)每个障碍物都要用一个几何形状来表示,这里采用包围球来标识场景中的每个障碍。
一种可能的方法是检测从AI角色向前延伸的ahead向量与障碍物的包围球是否相交。这种方法当然可以,但这里采用简化的方法,更容易理解,且能够达到相似的效果。
这里还需要一个向量ahead2,这个向量与ahead向量的唯一区别是:ahead2 的长度是ahead的一半,如图2.18所示。计算方法如下。
1ahead = position + normalize(velocity) × MAX_SEE_AHEAD × 0.5
(3)接下来进行一个碰撞检测,来测试这两个向量是否在障碍物的包围球内。方法很简单,只需要比较向量的终点与球心的距离d就可以了。如果距离小于或等于球的半径,那么就认为向量在包围球内,即AI角色将会和包围球发生碰撞。
如果ahead与ahead2中的任一向量在包围球内,那么就说明障碍物挡在前方。
如果有多个障碍挡住了路,那么选择最近的那个障碍(即“威胁最大”的那个)进行计算。
(4)接下来,计算能够将AI角色推离障碍物的操控力。可以利用球心和ahead这两个向量计算,方法如下:
1avoidance_force = ahead - obstacle_center
2
3avoidance_Force= normalize(avoidance_force) x MAX_AVOID_FORCE
这里,MaxAvoidForce 用于决定操控力的大小,值越大,将AI角色推离障碍物的力就越大。
采用这种方法的缺点是,当AI角色接近障碍而操控力正使它远离的时候,即使AI角色正在旋转,也可能会检测到碰撞。一种改进方法是根据AI角色的当前速度调整ahead向量,计算方法如下。
1dynamic_length = length(velocity) / MAX_VELOCITY
2
3ahead = position + normalize(velocity) × dynamic_length
这时,DynamicLength 变量的范围是0~1,当AI角色全速移动时,DynamicLength 的值是1。
群体的操控行为
组行为
正如大多数人工生命仿真一样,组行为是展示操控行为的一个很好的例子,它的复杂性来源于个体之间的交互,并遵守一些简单的规则。
模仿群体行为需要下面几种操控行为。
分离(Separation):避免个体在局部过于拥挤的操控力;
队列(Alignment):朝向附近同伴的平均朝向的操控力;
聚集(Cohesion):向附近同伴的平均位置移动的操控力。
检测附近的AI角色
从上面的几种操控行为可以看出,每种操控行为都决定角色对相邻的其他角色做出何种反应。为了实现组行为,首先需要检测位于当前AI角色“邻域”中的其他AI角色,这要用一个雷达脚本来实现。
一个角色的邻域由一个距离和一个角度来定义,当其他角色位于这个邻域内时,便认为是 AI 角色的邻居,否则将会被忽略。
与群中邻居保持适当距离——分离
分离行为的作用是使角色与周围的其他角色保持一定的距离,这样可以避免多个角色相互挤到一起。当分离行为应用在许多AI角色上时,它们将会向四周散开,尽可能地拉开距离。
实现时,为了计算分离行为所需的操控力,首先要搜索指定邻域内的其他邻居(通过前面的脚本实现),然后对每个邻居,计算AI角色到该邻居的向量 r,将向量 r 归一化($r / |r|$,这里 $|r|$ 表示向量$r$ 的长度),得到排斥力的方向,由于排斥力的大小是与距离成反比的,因此还需要除以 $|r|$,得到该邻居对它的排斥力,即 r/|r|2,然后把来自所有邻居的排斥力相加,就得到了分离行为的总操控力。
与群中邻居朝向一致——队列
队列行为试图保持AI角色的运动朝向与邻居一致,这样就会得到像鸟群朝着一个方向飞行的效果。
通过迭代所有邻居,可以求出AI角色朝向向量的平均值以及速度向量的平均值,得到想要的朝向,然后减去AI角色的当前朝向,就可以得到队列操控力。
队列行为对于集群并不是必须的,使用与否取决于具体应用。例如飞向目标的群鸟、沿着道路同向行驶的汽车就用到了队列行为。
成群聚集在一起——聚集
聚集行为产生一个使AI角色移向邻居的质心的操控力。这个操控力使得多个AI角色(如鸟)聚集到一起。
实现时,迭代所有邻居求出AI角色位置的平均值,然后利用靠近行为,将这个平均值作为目标位置。
个体与群体的操控行为组合
组行为的基础是分离、队列和聚集,根据实际需要,可以与前面的个体操控行为相结合,例如避开障碍、随机徘徊、靠近与抵达等,从而产生更复杂的行为。
寻找最短路径并避开障碍物——A Star 寻路
在即时战略游戏(Real-Time Strategy Game,简称RTS)中,玩家可以用鼠标选定一组单元,然后单击地图上的某个位置,或者某个要攻击的敌人,这时寻路模块便会为这组单元找到一条能够避开障碍物的路径,让这组单元能够通过这条路径到达指定的位置。这个功能就是路径规划,也称为“寻路”。
寻路是游戏人工智能中要解决的最基本的问题之一。游戏程序设计人员经常需要为一个AI角色规划出一条路径,让它能从游戏世界中的A点到达B点。
实现 A Star 寻路的3种工作方式
A Star 寻路方式通常有3种:基于单元的导航图、基于可视点导航图与导航网格。
方式1:创建基于单元的导航图
基于单元的导航图是将游戏地图划分为多个正方形单元或六边形单元组成的规则网格,网格点或网格单元的中心可以看作是节点。
这种表示方式最容易理解和使用,而且由于它的结构很规则,因此易于动态更新,如动态增加建筑物或其他障碍(如塔楼)等。基于单元的导航图比较适合在塔防游戏、即时战略游戏或其他频繁动态更新场景的游戏中使用。
采用基于单元的导航图时,寻路是以网格为单位进行的,缺点如下:
如果单个正方形过大,网格很粗糙,那么很难得到好的路径;而如果单个正方形很小,网格很精细,那么虽然会寻找到很好的路径,但这时需要存储和搜索大量的节点,对内存要求高,而且也很影响效率。
如果游戏环境中包含多种不同的地形(例如平原、沼泽、河流、山地),并且为每种类型设置了不同的代价(例如,士兵穿越沼泽需要付出很高的代价,而在平原上行走的代价却很小),这时寻路算法就会倾向于寻找平原上的路径,那么就需要为网格中的每个单元(正方形或六边形)记录地形信息。这也需要一定的开销。
如果是 RTS 游戏,还选择了基于单元的导航图进行寻路,那么游戏会面临更严峻的考验:假设同时有数十个单元需要寻找路径,那么占用的内存空间和消耗的CPU资源将会很大。
方式2:创建可视点导航图
另一个受欢迎的表示方式可以称为可视点导航图,也称为路点图。路点也称为“轨迹点”。
建立可视点导航图时,一般先由场景设计者在场景中手工放置一些“路径点”,然后由设计人员逐个测试这些“路径点”之间的可视性。如果两个点之间中间没有障碍物遮挡,即这两个点之间相互能“看到”,那么就可以用一条线段把这两个点连接起来,生成一条“边”(实际操作中,可能对“边”施加一些限制,例如,边的长度必须小于某个值等),最后,这些“路径点”和“边”就组成了可视点导航图。
可视点导航图的最大优点是它的灵活性。分散在各处的路径点是由场景设计者精心选择的,能覆盖绝大部分可行走的区域,还可以将其他一些重要位置的点包含进去,例如,理想的掩护位置、伏击位置等,同时增加相应的信息存储。利用这些可用信息,就可以高效地实现战术寻路,还可以计算出某个位置的战略信息,例如,是否是死胡同,是否安全等。
可视导航点的缺点如下:
当场景很大时,手工放置路径点是很繁琐的工作,也很容易出错。
它只是一些点和线段的集合,无法表示出实际的二维可行走区域,角色只能沿着那些边运动。当起始点或终点既不是路径点,也不在边上的时候,只能先找到距离最近的路径点,然后再进行寻路,这样,很可能会得到一条Z字形的路线,看上去很不自然。
现在的游戏中,越来越广泛地将导航网格用于寻路,这种方式大多将寻路与战术点分开,即导航网格只用于寻路,然后采用设计师手工放置躲藏点、埋伏点进行战术决策。
方式3:创建导航网格
导航网格(Navmesh)将游戏场景中的可行走区域划分成凸多边形。实现中也可以限制多边形的种类,例如,要求只能使用三角形,或可以同时使用三角形和四边形等。导航网格表示出了可行走区域的真实几何关系,是一个非均匀网格。Unity3D自带的寻路系统就建立在导航网格的基础上。
在这个三角形网格上进行 A Star 寻路时,每个节点不再对应于一个正方形,而是对应于一个三角形,所以相邻的节点即为与这个三角形相邻的其他三角形。另外,估计g和h时,导航网格方式也采用了不同的方法,例如,可以用三角形质心之间的线段长度作为节点之间的路径代价g,也可以用三角形的边的中点之间的距离作为g值等。
与前两种导航图相比,导航网格的优点是可以进行精确的点到点移动。由于在同一个三角形中的任意两个点都是直接可达的,因此可以精确地寻找到从起始点到目标点的路径。
另外,由于游戏场景本身就是由多边形构成的,因此,通过事先设计好的算法,就能够自动地将可行走区域划分成多边形,生成导航网格,而不需要人工干预。
用 A Star 算法实现战术寻路
在实际游戏中,很多时候,最短路径并不是最好的选择。需要寻路的AI角色可能是人类、也可能是善于游泳的怪物、坦克或舰船,它要面对多变的地形,如可能是山地、森林,也可能是沼泽、河流。每种AI角色都有自己的特点,可能很善于穿越某些地形,而对另一些地形却束手无策或笨手笨脚。例如,一个人类士兵可以很容易地在森林中穿梭行走,而坦克就有一些困难;另外,最好也不要让坦克在山地上行驶,因为这样可能会暴露它的底部,使它容易遭到攻击,而且坦克也不能急转弯(sharp turn)。
还有一些情况下,我们希望AI角色能够避开强火力区域,选择更为安全的路线,或是为了进行伏击,选择迂回隐蔽的路线。为了让AI角色更聪明灵活,就需要用到战术寻路。
这样就面临一个问题,当不想选择距离最短的路径,而希望考虑到其他因素,例如安全性、隐蔽性的时候,该怎样找到想要的路线呢?
实现战术寻路的思路其实很简单,就是为不同区域赋予不同的代价值。前面说过,A寻路的目标就是要寻找一条从起点到终点的总代价最小的路径,那么,要实现战术寻路,只需增加危险或困难的区域(例如强火力区域或沼泽等)的代价值,A就会尽量避开这些区域,而选择更安全或容易的路径。
A Star 寻路的适用性
A Star 寻路算法在游戏中具有十分广泛的应用,利用它可以找到一条从起点到终点的最佳路径,它的效率在同类算法中也很高,对于大多数路径寻找问题,它是最佳的选择。
有一些 A Star 寻路不太适用的场合。例如,如果起点和终点之间没有障碍物,终点直接在视线范围内,就完全不必采用它。另外,这个算法虽然高效,但寻路具有较大的工作量,需要多帧才能完成。如果CPU计算能力较弱,或者需要为大地形寻找路径,那么计算起来就比较困难了。
如果游戏设计者正在为一个 Android 平台下的手机游戏选择寻路算法,就更需要做好权衡。与PC相比,手机的内存资源要珍贵得多,如果需要在很大的空间中进行寻路,最好选择其他算法,并且,估价算法的开销也可能会成为瓶颈。在手机游戏中需要针对不同的寻路要求,选择不同的实现方法,例如采用深度优先算法、广度优先算法、遗传算法等。
在战斗游戏中,往往希望AI角色能快速从一个地方跑动到另一个地方。绝大多数情况下,想要的路径并不是最短路径。试想,如果一个敌人AI角色试图逃离玩家的枪弹,结果却是从玩家指挥的角色身边跑过去!虽然,路过玩家角色身边是一个很坏的选择,应该采用更好的路径搜索策略。
AI 角色对游戏世界的感知
当我们能够控制角色的移动时,会发现还有更多的问题需要处理,其中一个重要的问题就是角色如何感知周围的游戏世界。为了让AI角色看上去更真实也更有趣,必须使它能够以正常的感知方式知道周围发生了什么,并且能够对发生的事情做出适当的反应,这样,AI角色就会具有类似于人类的行为。例如,如果玩家扔出一个瓶子到AI角色附近,那么它会检测到瓶子落地的声音,并且找出扔瓶子的玩家的位置。
在游戏中,感知的开销可能会很大,通常情况下,每个角色都需要查询其他所有角色。假设游戏中有$n$ 个骑士,$n$ 个僵尸,骑士根据看到的僵尸数量决定自身行为。这时,假设对于每个僵尸,需要 $O(n)$ 时间确定数量的话,那么对于 $n$ 个骑士,总共就需要 $O(n2)$ 时间。因此,许多情况下,感知不能也不需要在每帧中进行。
AI角色对环境信息的感知方式
AI角色可以通过两种方式获得游戏世界的信息——轮询和事件驱动。简略地说,轮询是通过积极地观察世界的方式来获得信息,事件驱动是通过坐等消息的方式来获得信息。
AI角色自主决策——有限状态机
决策系统的任务是对从游戏世界中收集到的各种信息进行处理(包括内部信息和外部信息),确定AI角色下一步将要执行的行为。这些行为由两部分组成:一些行为会更改AI角色的外部状态,例如拨动开关、进入房间、开枪等;另一些行为只会引起内部状态的变化,例如改变AI角色的心情状态、改变总体目标等。
AI角色通过决策系统来确定下一步的行为,因此决策系统的重要性无需多言。幸运的是,相对于运动系统和感知系统来说,游戏设计者并不需要费太多力,利用有限状态机或行为树就可以构造出一个看上去不错的决策系统。
有限状态机(Finite State Machine: FSM)由一组状态(包括一个初始状态)、输入和根据输入及现有状态转换为下一个状态的转换函数组成。
有限状态机具有规则的结构,通过采用有限状态机,可以将AI角色的行为模式用一些状态和这些状态之间的转换来表示。
飞翔、行走、跑这些动词都是状态,累了、高兴、生气这些形容词也是状态,甚至一些名词也可以表示状态,它们都表示不同的行为方式或存在方式。对于游戏AI来说,状态的关键意义是:不同的状态对应不同的行为。
关于有限状态机(FSM),需要了解以下几点:
有限状态机是AI系统中最简单的,同时也是最为有效和最常用的方法。对于游戏中的每个对象,都可以在其生命期内区分出一些状态。例如,一个骑士可能正在武装自己、巡逻、攻击或在休息,一个农民可能在收集木材、建造房屋,或在攻击下保护自己。
当某些条件发生时,状态机从当前状态转换为其他状态。在不同的状态下,游戏对象会对外部激励做出不同的反应或执行不同的动作。有限状态机方法让我们可以很容易地把游戏对象的行为划分为小块,这样更容易调试和扩展。
用户编写的每个程序都是状态机。每当写下一个if语句的时候,就创造出了一段至少拥有两个状态的代码——写的代码越多,程序就可能具有越多的状态。Switch和if语句数量的爆发会让事情很快失去控制,程序会出现奇怪的bug,几乎不可能理解出现这些bug的原因,最后得到不可预知的后果。这样,该项目将很难理解和扩展。
有限状态机是AI中最容易的部分,但是也很容易出错。在设计有限状态机的时候,一定要认真地考虑清楚其中的每个状态和转换部分。
分层有限状态机
有限状态机在构建 AI 时是一个非常好用的工具,可一旦AI行为多了起来,就很容易引发过渡条件爆炸,变成意大利面式状态机。
让我们举个例子,在生活中,我们有吃饭、看书、看电视、睡觉、逛超市、买东西、付钱、打卡、工作、下班等等的状态。我们先试着用普通的状态机去实现。
flowchart LR
吃饭 --> 看书
吃饭 --> 逛超市
吃饭 --> 看电视
看书 --> 吃饭
看书 --> 逛超市
看书 --> 睡觉
看电视 --> 吃饭
看电视 --> 逛超市
看电视 --> 睡觉
逛超市 --> 买东西
买东西 --> 付钱
付钱 --> 打卡
打卡 --> 逛超市
打卡 --> 工作
工作 --> 下班
下班 --> 睡觉
下班 --> 逛超市
睡觉 --> 看电视
睡觉 --> 看书
仅仅是10个状态,已经让我们眼花缭乱,他们密集的像蜘蛛网一样,难以维护、难以扩展。如果再往上添加状态,还要考虑各个状态与新状态之间是否存在过渡,大大的增加了我们的工作量。
我们可以发现上面的10个状态其实是可以划分出生活场景的。比如吃饭、看书、看电视、睡觉我们一般在家里进行,逛超市、买东西、付钱我们一般在超市进行,打卡、工作、下班我们一般在公司进行。将在一个地方要做的事归到一个生活场景,这样把生活场景也看作一个行为状态,而这个行为状态里面还包括着小的生活状态。就是大状态机驱动小状态机,小状态机驱动状态。
flowchart LR
subgraph Home
吃饭 --> 看电视
吃饭 --> 看书
看书 --> 吃饭
看书 --> 睡觉
睡觉 --> 看电视
睡觉 --> 看书
看电视 --> 吃饭
看电视 --> 睡觉
end
subgraph Shop
逛超市 --> 买东西 --> 付钱
end
subgraph Work
打卡 --> 工作 --> 下班
end
Home --> Shop
Home --> Work
Shop --> Home
Shop --> Work
Work --> Home
Work --> Shop
分层有限状态机的概念
分层有限状态机(Hierarchical Finite State Machine: HFSM)分为三个部分:
最外部控制整个流程的大状态机。
在大状态机下的子状态机。
在子状态机下的状态。
大状态机可在同层下具有子状态机和状态。子状态机下还可以嵌套子状态机。所有状态机也和状态一样,具有进入、退出的状态。
分层有限状态机的工作流程
进入主状态机,切换至默认状态/子状态机。
主状态机检测过渡状态条件是否成立,如果成立,切换到对应状态/子状态机,退出当前状态/子状态机,进入状态/子状态机。
主状态机当前状态是一个子状态机,检测完主状态机的过渡状态条件后,去检测子状态机的过渡状态条件。
如果子状态机过渡状态条件成立,切换到对应子状态机下的状态,退出当前状态/子状态机,进入状态/子状态机。
AI角色的复杂决策——行为树
要让游戏里的AI角色能执行预设的逻辑,最直接的方法是依照行为逻辑直接编写代码,但是,这种方法工作量大,也很容易出错。我们也可以用有限状态机来实现行为逻辑,但是有限状态机难以模块化,编写代码麻烦且容易出错。相较而言,行为树(Behavior Tree)层次清晰,易于模块化,并且可以利用通用的编辑器简化编程,简洁高效。
行为树很适合用做AI编辑器,它为设计者提供了丰富的流程控制方法。只要定义好一些条件和动作,策划人员就可以通过简单的拖拽和设置,来实现复杂的游戏AI。
行为树技术原理
行为树主要采用4种节点(在行为树中,“节点”也称为“任务”)来描述行为逻辑,分别是顺序节点、选择节点、条件节点和行为节点。每一棵行为树表示一个AI逻辑。要执行这个AI逻辑,需要从根节点开始遍历执行整棵树。遍历执行的过程中,父节点根据自身的类别,确定需要如何执行、执行哪些子节点并继而执行,子节点执行完毕后,会将执行结果返回给父节点。
节点从结构上分为两类:组合节点、叶节点。所谓组合节点就是树的中间节点,例如,上面提到的顺序节点和选择节点都是组合节点;叶节点一般用来放置执行逻辑和条件判断,上面提到的条件节点和行为节点都是叶节点。
实际应用时,可以事先由策划人员设计好行为树的结构,程序员只需实现条件节点和行为节点所定义的具体行为即可,也可以由编程人员预先写好各种不同的条件节点和行为节点的相应代码,供策划人员选用。然后,策划人员可以尝试将这些条件和行为进行不同的组合,画出不同的行为树,从而实现不同的AI逻辑。
使用行为树与有限状态机的权衡
这些年来,行为树在游戏AI中已经十分常见,但它并不能够完全替代有 限状态机,应用的时候应加以权衡,了解它们不同的适用性。
- 对于状态机来说,每个时刻它都处于某种“状态”中,等待某个事件(转换)的发生。如果事件没有发生,那么继续保持在这个状态;如果事件发生,那么转换到其他状态。因此,状态机本质上是“事件驱动”的,即 周围游戏世界发生的“事件”驱动角色的“状态”变化。
2. 状态机既可以采用轮询的方式实现(每帧主动查询是否发生了某种事件),也可以采用事件驱动的方式实现(例如,注册一个回调函数,每当事件发生时,调用这个函数,在其中改变状态机的状态,或是利用消息,当事件发生时,发送消息)。
对于行为树,处理周围游戏世界的变化的任务是由条件节点来完成 的,这相当于每次遍历行为树时,条件节点都向周围世界发出某种“询问”,以这种方式来监视游戏世界发生的事情。因此,这实际上是“轮询” 的方式——不断地主动查询。
一般来说,行为树不太适合表示需要事件驱动的行为。例如,AI 角色需要对大量外部事件做出反应——当 AI 角色正在向某个目标移动时,突然发生了某个事件,如同伴需要救援、玩家被击中等事件,需要立即终止这个移动过程,重新做出新的决策等。
AI 角色的复杂决策 —— HTN
Hierarchical Task Network(分层任务网络),简称HTN,与行为树、GOAP一样,也是一种行为决策方法。在《地平线:零之曙光》、《变形金刚:塞伯坦的陨落》中都有用它来制作游戏敌人的AI。比起其它行为决策方法,HTN有个十分鲜明的特点:推演。
HTN允许我们把要做的事以高度复杂的「复合任务」来表示,而不是单单一个行为。什么意思呢?无论是有限状态机状态的转换,还是行为树节点的切换,大多时候只是从一个执行动作变为执行另一个动作。而HTN的一次规划,可以一口气规划出包含好几个动作的「复合任务」,你看到它做出的新动作,也不过是之前就计划好的一部分。
HTN的整体结构框架如下:
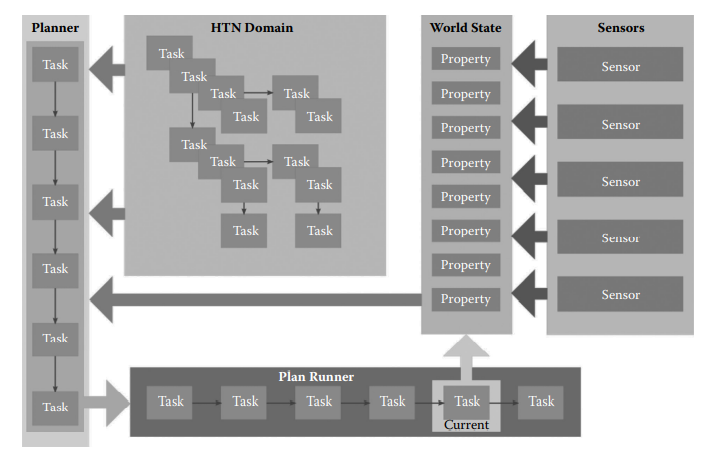
任务
首先,和其它行为决策方法一样,角色内部有存储一系列要做的事。在有限状态机中是「状态」,行为树中是「动作节点」,而HTN中是 「任务(Task)」。但要注意,HTN的「任务」十分特殊,它不只是单一的动作,可能包含多个动作,总的可以分为三种:「复合任务」、「方法」以及「原子任务」。
- 原子任务,是最简单的任务,只是单一的动作,像「奔跑」、「跳跃」等就算是原子任务。通常也不建议把一个原子任务设计得太复杂。
- 复合任务,复合任务是由多个「方法」组合而成的,而每次执行复合任务,只会选择组成它的众多「方法」之一来执行,就像行为树的选择节点一样。
- 方法,方法是HTN让角色行动丰富的关键,一个方法可以由多个「原子任务」或「复合任务」组合而成。在「方法」的帮助下,我们可以自然且清晰地构建丰富的行为。以「砍树」为例,可以构造成这个样子:
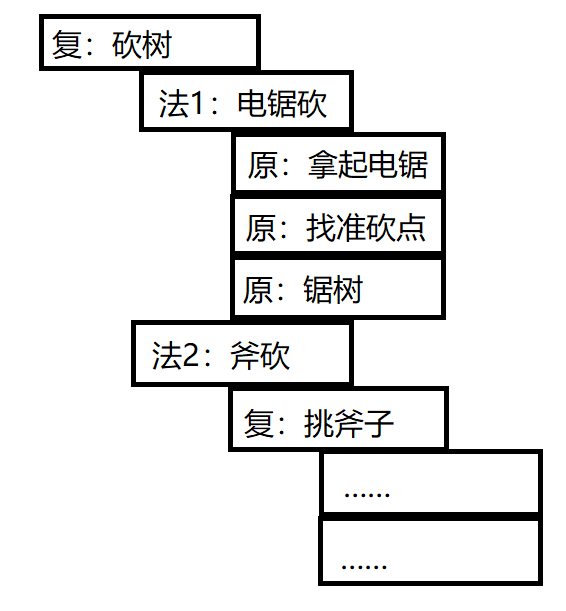
方法的执行,会逐一判断组成的「复合任务」和「原子任务」是否满足条件,只要有一个不满足,这个方法便会被放弃,它有点像行为树中的顺序节点。
这里要多说一嘴,「复合任务」和「方法」只会在HTN的规划阶段被执行。所谓「规划阶段」,就是根据「世界状态」来决定该做什么事,规划时会把要做的「复合任务」和「方法」统统分解成一个个「原子任务」。也就是说,最终角色实际执行的都是「原子任务」。
世界状态
在游戏常用的决策行为算法中,只有GOAP和HTN有用到「世界状态」。其实这是更接近传统人工智能的设计方式(GOAP和HTN也确实是由传统人工智能转变来的),还是以「砍树」为例,想要让一个角色去砍树,他就得知道:哪里有树、哪里有电锯、电锯有多少油……这些 做事的前提 都可以归为「世界状态」的一员,反过来说,世界状态就是这类「前提条件」的集合,它们共同构成了HTN任务规划的基础。
在规划阶段,角色会复制一份「世界状态」的副本用于个人判断并选出可执行的任务,就好像是侦探拿着照片进行脑补推断一样。这个过程不会影响真正的「世界状态」。而在选出了可执行的任务后,就会将它分解成一系列「原子任务」挨个执行。有些(或者说大多数)「原子任务」执行完成后会对「世界状态」造成一定影响,比如开枪会减少弹药数,锯完树会减少树木数量等等。但要注意,这里的影响就不再是“脑补”的啦,而是真正改变「世界状态」的某些值。就像是部队制定完计划后,就开始正式行动了。
世界状态实现的难点在于:
- 状态数据的类型是多种多样的,该用什么来统一保存?
- 状态数据会时时变化,如何保证存储的数据也会同步更新?
对于问题1,我们可以用 <string, object> 的字典来解决。毕竟C#中,object类是所有数据类型的老祖宗。那问题2呢,假设用这种字典存储了某个角色的血量,那这个角色就算血量变成0了,字典里存储的也只是刚存进去时的那个值而不是0。而且反过来,我们修改字典里的这个血量值,也不会影响实际角色的血量……除非,这些值能像属性一样……
这是可以做到的!但要用到两个字典,一个用来模仿属性的get,一个用来模仿属性的set。分别用值类型为 System.Action<object> 和 System.Func<object> 的字典就可以了。
总结
根据世界状态来选择要执行的任务,再将选好的任务分解为一个个原子任务来执行,而原子任务执行完后又会影响世界状态。一旦分解出的原子任务都执行完了,又或者某个原子任务的执行条件突然不能满足了,就重新选择,重复这个步骤。这就是HTN大体的运行逻辑了。
游戏AI行为决策 —— GOAP
像先前提到的有限状态机、行为树、HTN,它们实现的AI行为,虽说能针对不同环境作出不同反应,但应对方法是写死了的。有限状态机终究是在几个状态间进行切换、行为树也是根据提前设计好的树来搜索……你会发现,游戏AI角色表现出的智能程度,终究与开发者的设计结构有关,就有限状态机而言,各个状态如何切换很大程度上就影响了AI智能的表现。
那有没有什么决策方法,能够仅需设计好角色需要的动作,而它自己就能合理决定要选择哪些动作完成目标呢?这样的话,角色AI的行为智能程度会更上一层楼,毕竟它不再被写死的决策结构束缚;我们在添加更多AI行为时,也可以简单地直接将它放在角色需要的动作集里就好,减少了工作量,不必像行为树那样,还要考虑节点间的连接。
没错,GOAP就可以做到。(咳咳,虽说为了突出GOAP的特点进行了一番拉踩(ˉ▽ˉ;)。但请注意,并不是说GOAP就比其它决策方法好,后面也会提到它的缺点。选择何种决策方法还得根据实际项目和自身需求)
PS:本教程需要你具备以下前提知识:
- 知道数据结构 堆/优先队列、栈、图
- 知道A星寻路的流程
- 基本的位运算与位存储(能做到理解Unity中的Layer和LayerMask的程度就行)
GOAP的规划l类似于 A 星算法。只是把每个节点都当成一个状态,每条道路都当作一个动作、道路长度作为动作代价、路口的门作为动作执行条件,然后像你这样寻找出一条可以执行的最短「路线」,并记录下途径的道路(注意,不是节点)这样就得到了 「动作序列」,再让AI角色逐一执行。
GOAP就是在不断执行「从现有状态到目标状态」。可想而知,只要状态够多,动作够多,AI就能做出更复杂的动作。虽说这对其它决策方法也成立,但GOAP不需要我们显示地手动设置各动作、状态之间的关系,它能自行规划出要做的一系列动作,更省事且更智能,甚至可以规划出超出原本设想但又合理的动作序列。
世界状态
所谓「世界状态」其实就是存储所有的状态放在一块儿的合集。而状态其实还有一个隐藏身份——动作条件。是的,状态也充当了动作的执行条件,比如之前图中的条件「有流量」,它其实也是一个状态。
世界状态会因 自然因素 变化,比如「饱」会随着时间流逝而变「饿」;也会因角色自身的一些 动作导致 变化,比如一个角色多运动,也会使「饱」变「饿」。
问题在于:
- GOAP规划需要时时获取最新的状态,才能保证规划结果的合理性(否则饿晕了还想着运动);
- 世界状态」中有些状态是「共享」的,比如之前说的时间,但还有一些状态是私有的,比如「饱」,是我饱、你饱还是他饱?在一个合集里该如何区分?
PS:在传统人工智能Agent中,对于环境的表示方式有三种:
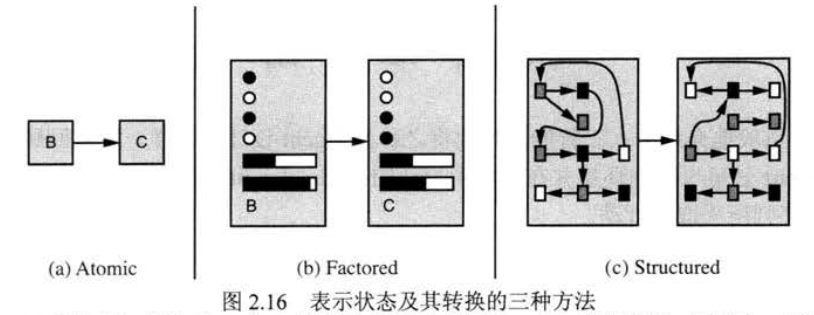
- 原子表示(Atomic):就是单纯描述某个状态有无,通常每个状态都只用布尔值(True/False)表示就可以,比如「有流量」。
- 要素化表示(Factored):进一步描述状态的具体数值,这时,状态可以有不同的类型,可以是字符串、整数、布尔值……在HTN中,我们就是用这种方式实现的。
- 结构化表示(Structured):再进一步,每个状态不但描述具体数值,还存储于其它数据的连接关系,就像数据结构中「图」的节点那样。
将世界状态分为「私有」和「共享」,我们就可以让角色更新「私有」部分,而全局系统更新「共享」部分。当需要角色规划时,我们就用位运算将该角色的「私有」与世界的「共享」进行整合,得到对于这个角色而言的当前世界状态。这样对于不同角色,它们就能得到对各自的而言的世界状态啦!
动作
我们之前说过,动作包含一个「前提条件」,其实和 HTN 一样,它还包含一个「行为影响」,相当于之前图中道路指向的椭圆表示的状态。它们也都是世界状态,注意是世界状态,而不是单个状态!
为什么不设置成单个?首先,「前提条件」和「行为影响」本身就可能是多个状态组合成的,用单个不合适;其次,将它们也设置成世界状态(64位的long类型),方便进行统一处理与位运算。Unity中的Layer不也是这样,对吧。
只有当前世界状态与「前提条件」对应位的值相同时,才算满足前提条件,这个动作才有被选择的机会。而动作一旦执行成功,世界状态就会发送变化,对应位上的值会被赋值为「行为影响」所设置的值。
Reference
《Unity3D人工智能编程精粹》
《游戏AI程序设计实战》
《Game AI Pro》
《Game AI Pro 2》